Introduction
Problem Statement
In this project, we want to use big compute techniques to parallelize the algorithms of image stitching, so that we can stream videos from adjascent camera into a single panoramic view.
Image stitching or photo stitching is the process of combining multiple photographic images with overlapping fields of view to produce a segmented panorama or high-resolution image (example below).

Procedures of Image Stitching
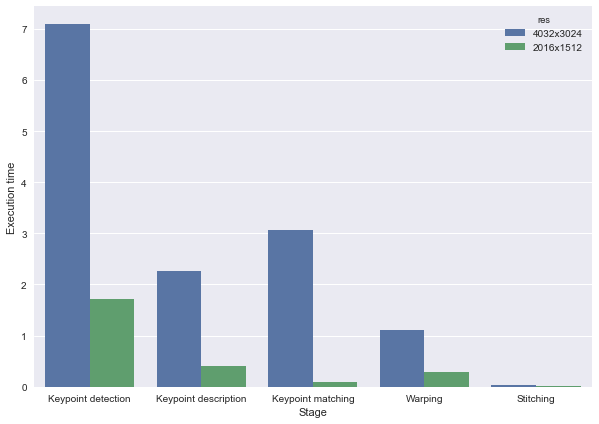
Image stitching is a rather complicated application in computer vision. It is composed of several key stages, some of which involve heavy computation. We will give an intuitive explanation of each of the key procedures below. Please follow the links provided for more technical details, and please refer to the Design Approach section for a complexity profiling of these tasks.
- Keypoint Detection and Description
- Keypoint Matching
- Transformation Estimation
- Warping
- Stitching
- Border Blending
As a first step, keypoints on the two images you want to stitch together need to be identified. These keypoints usually correspond to the most distinguish features of an image, such as corners and edges of an object. There are several famous algorithms that dedicately achieve this task, including Harris Corner Detection, Scale Invariant Feature Transform (SIFT) and Speed-Up Robust Features (SURF). SIFT and SURF are the state-of-the-art due to their robustness.
Not only do these algorithms identify the keypoints, they will also generate a descriptor vector for each of the keypoints. These descriptors will capture information about the keypoints' location, orientation and relation to their surroundings.
After keypoint detection, each image will have a set of keypoints together with their descriptor vectors. We will then need to establish matching relations between these descriptors. Most methods are based on Euclidean distance between descriptors. For each keypoint in image 1, if its best match is significantly better than the second best match, then we consider the best match valid.
Once we have establish matching keypoints between images, we want to estimate a transformation matrix H that will be used to warp the image. Normally, Random Sample Consensus (RANSAC) will be used to derive reliable transformation matrix after removing false matches. The algorithm basically iteratively try out different match combinations and only keep the one that is the best-fitting to the matches.
With the transformation matrix, we can project the image to the right to the plane that the image to the left is at. This is called warping.
Finally, we have the original image 1, and the warped image 2. We can stitch them together by placing pixels from both images on a blank canvas.
Border blending is to smooth out the differences in light and hue across the stitching seam, so that the stitched image can look more homogeneous.
Need for High Performance Computing
The key idea of our project is to focus on the word ‘real-time’. Although there are existing algorithms for the application, doing it in ‘real-time’ can still be challenging.
Imagine the scenario where we need a real-time panorama streaming view, this would require the backend application to stitch the view of different cameras together frame by frame. For a laggy video of 5 frames per second, we will need processing time of at most 0.2 seconds for each pair of images. This would be very difficult to achieve with regular computational resources. With a faster stitching process of one pair of images, we can process more image pairs per second, which would result in a higher Frames Per Second (FPS). FPS is a direct measure of how fluid the video looks to human eyes.
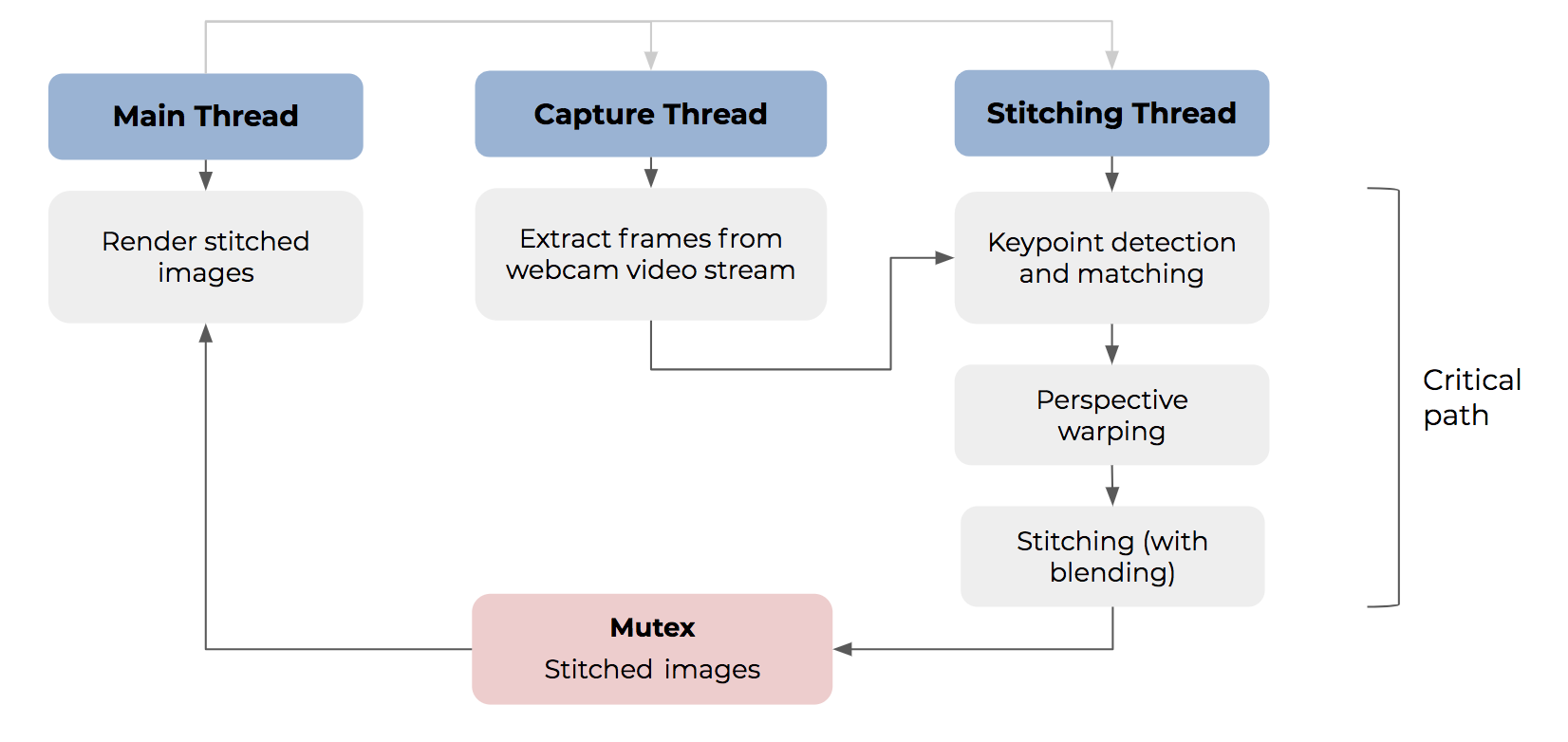
In addition, most of the existing real-time stitching solution assume all of the cameras stay still during the whole streaming process. In this way it only require one single iteration of detecting features, matching features and estimating transformation. However, this assumption posed too much limitation on the application of this problem. We, however, do not have such assumption in our project. Ideally, we want to be able to stitch the view of several handheld cameras. The price we need to pay, is that we will need to detect features, match features and estimate transformations at each frame of the video. This will require us to further accelerate the code while ensuring the quality of the overall stitching result.
In addition, with high performance computing, we can stitch images of higher resolution, at a visually fluid speed. This is the whole motivation of parallelizing the task of image stitching.
Challenges
There are several challenges associated with our project:
- Some algorithm such as SIFT or SURF is rather complicated to understand as well as to re-implement. They are not composed solely of independent loops, but have many data dependencies that need to be dismantled before parallelization.
- The desirable speedup might be challenging to achieve. The sequential version will take only a few seconds to run once. This means overheads such as memory access, synchronization and communication are by no means negligible. Speeding it up to achieve multiple frames per second entails careful optimization of overheads.
- The program might be heavily memory bound, as a high resolution image will have millions of pixels, and we can potentially find a large amount of keypoints. Accessing and communicating the original images and these keypoints together with their descriptors will add to the execution time.
- Our parallelization target is not a single algorithm. It is a sequence of algorithms achieving different tasks. We need to consider the possibility of task-level scheduling and parallelization of these different tasks.
- This problem is nauturally a realtime programming problem, which implies it might be easily affected by many subtle problems in design and scheduling of the whole process.